


רגרסיה פולינומית
סקירה כללית
בדוגמאות הקודמות של רגרסיה ליניארית, כאשר הנתונים משורטטים על הגרף, היה קשר ליניארי בין המשתנים התלויים והבלתי תלויים. לפיכך, היה מתאים יותר לבנות מודל ליניארי כדי לקבל תחזיות מדויקות. מה אם לנקודות הנתונים הייתה האי-לינאריות הבאה, מה שגורם למודל הליניארי לתת שגיאה בתחזיות עקב אי-לינאריות?
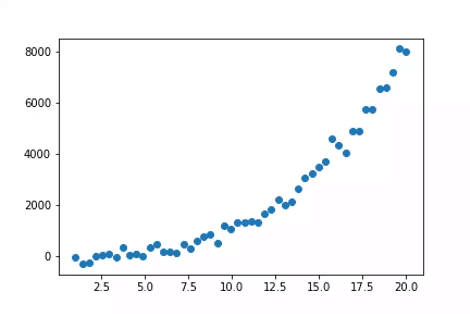
נקודות נתונים לא ליניאריות (מקור)
במקרה זה, עלינו לבנות קשר פולינומי שיתאים במדויק לנקודות הנתונים בחלקה הנתונה. זה נקרא רגרסיה פולינומית. הנוסחה של עקומת רגרסיה פולינומית ניתנת כ-y=w1x+w2x²+..+b
להלן ה-GIF של התאמת מודל רגרסיה לינארית ומודל רגרסיה פולינומית על נתונים לא ליניאריים.
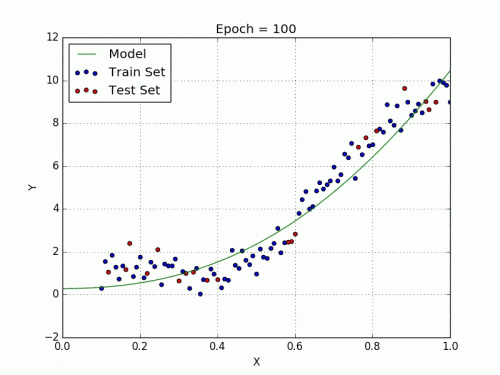
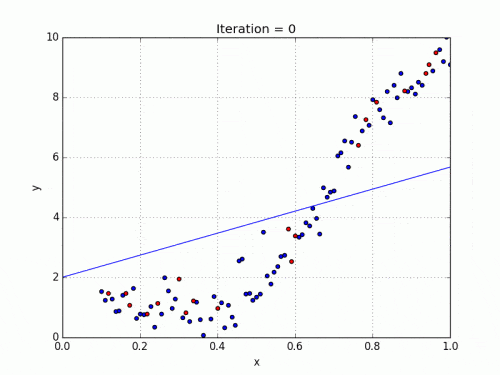
כפי שאנו יכולים לראות, הרגרסיה הליניארית תמיד נוטה לעשות שגיאה ככל שתנסה להשתלב בנתונים. מצד שני, גרף רגרסיה פולינומית מצליח להתאים את נקודות הנתונים על הקו בצורה מדויקת יותר.
בדוגמה זו, נעבור על יישום רגרסיה פולינומית, בה נחזה את השכר של עובד חדש על סמך רמת התפקיד שלו בחברה הקודמת שלו מנתוני השכר עבור אותן רמות תפקיד בחברה החדשה.
ניתוח הבעיה
בנתונים אלה, יש לנו את שני המשתנים הבלתי תלויים, כלומר, מיקום ורמה. יש משתנה אחד בלתי תלוי כלומר שכר. לכן, בבעיה זו עלינו לאמן מודל רגרסיה פולינומית עם הנתונים הללו כדי להבין את המתאם בין הרמה והשכר של נתוני העובדים בחברה ולהיות מסוגלים לחזות את השכר לעובד החדש על סמך הנתונים הללו.
שלב 1: ייבוא הספריות
בשלב ראשון זה, נייבא את הספריות הנדרשות לבניית מודל ה-ML. ספריית NumPy וה-matplotlib מיובאים. בנוסף, ייבאנו את ספריית Pandas לניתוח נתונים.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
שלב 2: ייבוא מערך הנתונים
בשלב זה, נשתמש בפנדות כדי לאחסן את הנתונים שהתקבלו ממאגר ה-github ולאחסן אותם כ-Pandas DataFrame באמצעות הפונקציה "pd.read_csv".
אנו עוברים על מערך הנתונים שלנו ומקצים את המשתנה הבלתי תלוי (x) לעמודה השנייה עם שם העמודה "רמה" ואת המשתנה התלוי (y) לעמודה האחרונה, שהיא ה"שכר" שיש לחזות.
dataset = pd.read_csv('https://raw.githubusercontent.com/mk-gurucharan/Regression/master/PositionSalaries_Data.csv')X = dataset.iloc[:, 1:-1].values
y = dataset.iloc[:, -1].valuesdataset.head(5)>>
Position Level Salary
Business Analyst 1 45000
Junior Consultant 2 50000
Senior Consultant 3 60000
Manager 4 80000
Country Manager 5 110000
אנו משתמשים בפונקציית .iloc המקבילה כדי לחתוך את ה-DataFrame כדי להקצות את האינדקסים הללו ל-X ו-Y. בכך, הרמה נלקחת כמשתנה הבלתי תלוי ומוקצה ל-X. המשתנה התלוי שיש לחזות הוא העמודה האחרונה ( -1) שהיא משכורת והיא מוקצה ל-y. אנו מדפיסים את "ערכת הנתונים" של DataFrame כדי לראות אם יש לנו את העמודות הנכונות עבור נתוני התרגיל שלנו על נושאים נוספים נעבור ב קורס Machine learning.
שלב 3: תרגול מודל הרגרסיה הפולינומית על כל מערך הנתונים
למערך הנתונים שבו אנו משתמשים יש מספר מעט מאוד של שורות, ולכן אנו מאמנים את מערך הנתונים כולו לבניית מודל הרגרסיה הפולינומית. בפונקציה הזו משתמשים בפונקציה "PolynomialFeatures" כדי להקצות את דרגת הקו הפולינומי שאנו הולכים לצייר. בכך התואר נקבע כ-4.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
poly_reg = PolynomialFeatures(degree = 4)
X_poly = poly_reg.fit_transform(X)
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y)
המחלקה "LinearRegression" מיובאת גם היא והיא מוקצית למשתנה "lin_reg" שמצויד ב-X_poly וב-y לבניית המודל.
שלב 4: חיזוי התוצאות
בשלב זה, אנו הולכים לחזות את הערכים משכורת בהתבסס על מודל הרגרסיה הפולינומית שנבנה. הפונקציה "regressor.predict" משמשת לניבוי הערכים עבור המשתנה הבלתי תלוי שלנו, X_poly. אנו מקצים את הערכים החזויים כ-y_pred. כעת יש לנו שני נתונים, y(ערכים אמיתיים) ו-y_pred (ערכים חזויים).
y_pred = lin_reg.predict(X_poly)
שלב 5: השוואת הערכים האמיתיים עם הערכים החזויים
בשלב זה, נדפיס הן את הערכים של y כערכים אמיתיים והן ערכי y_pred כערכים חזויים של כל מבחן X_ ב-Pandas DataFrame.
df = pd.DataFrame({'Real Values':y, 'Predicted Values':y_pred})
df>>
Real Values Predicted Values
45000 53356.643357
50000 31759.906760
60000 58642.191142
80000 94632.867133
110000 121724.941725
150000 143275.058275
200000 184003.496504
300000 289994.172494
500000 528694.638695
1000000 988916.083916
אנו יכולים לראות שהמודל עשה עבודה מצוינת בהתאמת הנתונים ובניבוי השכר של העובד על פי רמת התפקיד.
שלב 6: הדמיית תוצאות הרגרסיה הפולינומית
בשלב אחרון זה, נדמיין את המודל הפולינומי שנבנה באמצעות הנתונים הנתונים, ונתווה את הערכים של "y" ו-"y_pred" על הגרף וננתח את התוצאות
X_grid = np.arange(min(X), max(X), 0.1)
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(X, y, color = 'red')
plt.scatter(X, y_pred, color = 'green')
plt.plot(X_grid, lin_reg.predict(poly_reg.fit_transform(X_grid)), color = 'black')
plt.title('Polynomial Regression')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
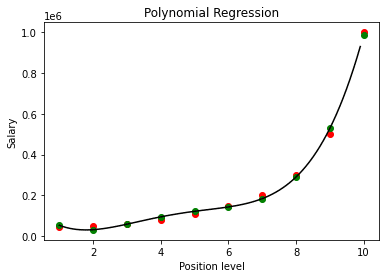
מודל רגרסיה פולינומית
בגרף זה, הערכים האמיתיים משורטטים בצבע "אדום" והערכים החזויים משורטטים בצבע "ירוק". קו הרגרסיה הפולינומית שנוצר מצוייר בצבע "שחור".
אני מצרף קישור של מאגר ה-github שבו אתה יכול למצוא את המחברת של Google Colab ואת קבצי הנתונים.
https://github.com/mk-gurucharan/Regression
מקווה שהצלחתי להסביר בבירור את התוכנית לבניית מודל רגרסיה פולינומית אשמח להסביר עודב קורס Machine learning..





